








How to Identify Malicious Bots on your Network in 5 Steps

|
Listen to post:
Getting your Trinity Audio player ready...
|
It’s no secret that malicious bots play a crucial role in the security breaches of enterprise networks. Bots are often used by malware for propagation across the enterprise network. But identifying and removing malicious bots has been complicated by the fact that many routine processes in an operating environment, such as the software updaters, are also bots.
Until recently there hasn’t been an effective way for security teams to distinguish between such “bad” bots and “good” bots. Open source feeds and community rules purporting to identify bots are of little help; they contain far too many false positives. In the end, security analysts wind up fighting alert fatigue from analyzing and chasing down all of the irrelevant security alerts triggered by good bots.
At Cato, we faced a similar problem in protecting our customers’ networks. To solve the problem, we developed a new approach. It’s a multi-dimensional methodology implemented in our security as a service that identifies 72% more malicious incidents than would have been possible using open source feeds or community rules alone.
Best of all, you can implement a similar strategy on your network. Your tools will be the stock-and-trade of any network engineer: access to your network, a way to capture traffic, like a tap sensor, and enough disk space to store a week’s worth of packets. Here’s how to analyze those packet captures to better protect your network.
The Five Vectors for Identifying Malicious Bot Traffic
As I said, we use a multi-dimensional approach. Although, no one variable can accurately identify malicious bots, the aggregate insight from evaluating multiple vectors will pinpoint them. The idea is to gradually narrow the field from sessions generated by people to those sessions likely to indicate a risk to your network.
Our process was simple:
- Separate bots from people
- Distinguish between browsers and other clients
- Distinguish between bots within browsers
- Analyze the payload
- Determine a target’s risk
Let’s dive into each of those steps.
Separate Bots from People by Measuring Communication Frequency
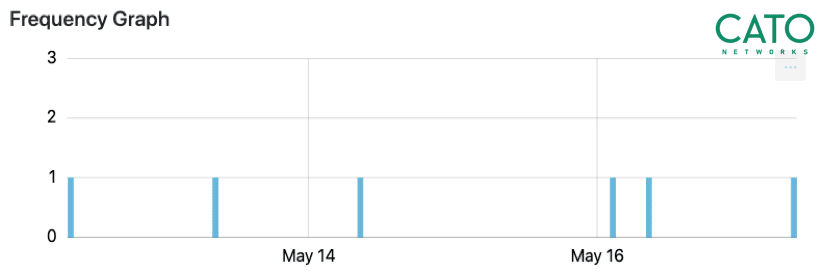
Bots of all types tend to communicate continuously with their targets. It happens since bots need to receive commands, send keep-alive signals, or exfiltrate data. A first step then to distinguishing between bots and humans is to identify those machines repeatedly communicating with a target.
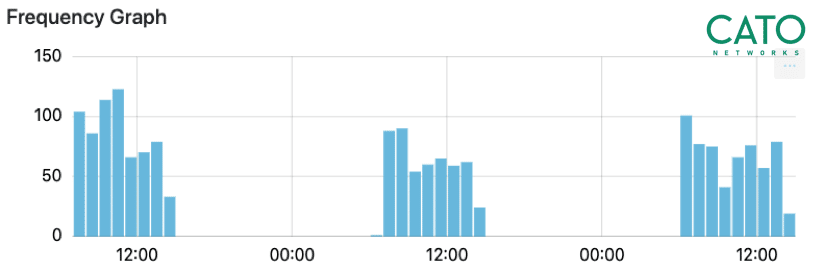
And that’s what you want to find out: the hosts that communicate with many targets periodically and continuously. In our experience, a week’s worth of traffic is sufficient to determine the nature of client-target communications. Statistically, the more uniform these communications, the greater the chance that they are generated by a bot (see Figure 1).
Join Our Cyber Security Masterclass –From Disinformation to Deepfake
Distinguish Between Browsers and Other Clients
Simply knowing a bot exists on a machine alone won’t help very much: as we said most machines generate some bot traffic. You then need to look at the type of client communicating on the network. Typically, “good” bots exist within browsers while “bad” will operate outside of the browser.
Operating systems have different types of clients and libraries generating traffic. For example, “Chrome,” ”WinInet,” and “Java Runtime Environment” are all different client types. At first, client traffic may look the same, but there are some ways to distinguish between clients and enrich our context.
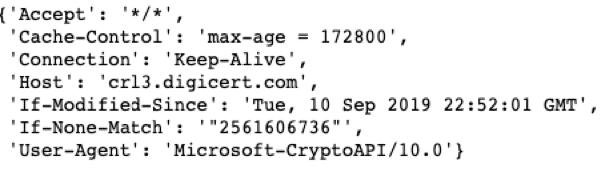
Start by looking at application-layer headers. Since most firewall configurations allow HTTP and TLS to any address, many bots use these protocols to communicate with their targets. You can identify bots operating outside of browsers by identifying groups of client-configured HTTP and TLS features.
Every HTTP session has a set of request headers defining the request, and how the server should handle it. These headers, their order, and their values are set when composing the HTTP request (see Figure 2). Similarly, TLS session attributes, such as cipher suites, extensions list, ALPN (Application-Layer Protocol Negotiation), and elliptic curves, are established in the initial TLS packet, the “client hello” packet, which is unencrypted. clustering the different sequences of HTTP and TLS attributes will likely indicate different bots.
Doing so, for example, will allow you to spot TLS traffic with different cipher suites, for example. It’s a good indicator that the traffic is being generated outside of the browser – a very non-human like approach and hence a good indicator of bot traffic.
Distinguish Between Bots within Browsers
Another method for identifying malicious bots is to look at specific information contained in HTTP headers. Internet browsers usually have a clear and standard headers image. In a normal browsing session, clicking on a link within a browser will generate a “referrer” header that will be included in the next request for that URL. Bot traffic will usually not have a “referrer” header or worse, it will be forged. Identifying bots that look the same in every traffic flow likely indicates maliciousness.

User-agent is the best-known string representing the program initiating a request. Various sources, such as fingerbank.org, match user-agent values with known program versions. Using this information can help identify abnormal bots. For example, most recent browsers use the “Mozilla 5.0” string in the user-agent field. Seeing a lower version of Mozilla or its complete absence indicates an abnormal bot user agent string. No trustworthy browser will create traffic without a user-agent value.
Analyze the payload
Having said that, we don’t want to limit our search for bots only to the HTTP and TLS protocols. This can be done by looking beyond those protocols. For example IRC protocol, where IRC bots have played a part in malicious botnets activity. We have also observed known malware samples using proprietary unknown protocols over known ports and such could be flagged using application identification.
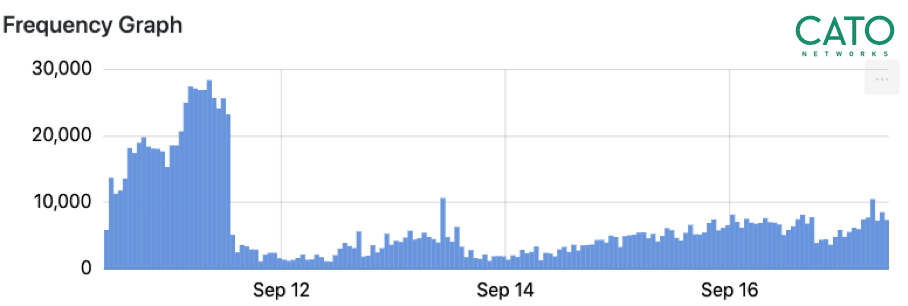
In addition, the traffic direction (inbound or outbound) has a significant value here.
Devices which are connected directly to the Internet are constantly exposed to scanning operations and therefore these bots should be considered as inbound scanners. On the other hand, scanning activity going outbound indicates a device infected with a scanning bot. This could be harmful for the target being scanned and puts the organization IP address reputation at risk. The below graph demonstrates traffic flows spikes in a short timeframe. Such could indicate scanning bot activity. This can be analyzed using flows/second calculation.
Target Analysis: Know Your Destinations
Until now we’ve looked for bot indicators in the frequency of client-server communications and in the type of clients. Now, let’s pull in another dimension — the destination or target. To determine malicious targets, consider two factors: Target Reputation and Target Popularity.
Target Reputation calculates the likelihood of a domain being malicious based on the experience gathered from many flows. Reputation is determined either by third-party services or through self-calculation by noting whenever users report a target as malicious.
All too often, though, simple sources for determining targets reputation, such as URL reputation feeds, alone are insufficient. Every month millions of new domains are registered. With so many new domains, domain reputation mechanisms lack sufficient context to categorize them properly, delivering a high rate of false positives.
Putting It All Together
Putting all of what we learned together, sessions identified as:
- Created by a machine rather than a human
- Generated outside of the browser or are browser traffic with anomalous metadata
- Communicating with low popularity targets, particularly those that are uncategorized or marked as malicious will likely be suspicious. Your legitimate and good bots should not be communicating with low-popularity targets.
Practice: Under the network hood of Andromeda Malware
You can use a combination of these methods to discover various types of threats over your network. Let’s look at one example: detecting the Andromeda bot. Andromeda is a very common downloader for other types of malware. We identify Andromeda analyzing data using four of the five approaches we’ve discussed.
Target Reputation
We noticed communication with “disorderstatus[.]ru” which is a domain identified as malicious by several reputation services. Categories of this site from various sources appear to be: “known infection source; bot networks.” However, as noted, alone that’s insufficient as it doesn’t indicate if the specific host is infected by Andromeda; a user could have browsed to that site. What’s more, as noted, your URL will be categorized as “unknown” or “not malicious.”
Target Popularity
Out of ten thousand users, only one user’s machine communicates with this target, very unusual. This gives the target a low popularity score.
Communication Frequency
Over one week we have seen continuous traffic for three days been the client and the target. The repetitive communication is again another indicator of a bot.
Header Analysis
The requesting user-agent is “Mozilla/4.0”, an invalid modern browser, indicating the user agent is probably a bot.

Summary
Bot detection over IP networks is not an easy task, but it’s becoming a fundamental part of network security practice and malware hunting specifically. By combining the five techniques we’ve presented here, you can detect malicious bots more efficiently.
Follow the links to learn more about our security services, Cato Managed Threat Detection and Response service and SASE platform.
Related Articles
Cato CTRL Threat Brief: CVE-2024-6387 – OpenSSH RCE Vulnerability (“regreSSHion”)


When Patch Tuesday becomes Patch Monday - Friday

Fake Data Breaches: Why They Matter and 12 Ways to Deal with Them

