








An Inside Look at Cato’s New AI Assistant


|
Listen to post:
Getting your Trinity Audio player ready...
|
In line with our philosophy of delivering an exceptional customer experience, Cato Networks has added a knowledge-base AI assistant as part of the Cato SASE Cloud Platform. The AI assistant provides accurate, relevant answers to questions about using Cato’s many capabilities with detailed, step-by-step instructions uniquely suited to the user’s situation and circumstance.
This is just the latest example of our AI work here at Cato. We recently announced our use of Amazon Bedrock as the basis of our generative AI (GenAI) capabilities. Amazon Bedrock powers our AI assistant and also natural language search (NLS), which enables free text inputs to be converted into technical search filters on our SASE platform. Cato’s AI and ML page provides additional examples of how we use AI/ML technologies, such as for threat intelligence, threat prevention, and classification of clients, devices, and applications.
Why an AI Assistant with Information Retrieval?
Cato has long offered robust search capabilities within its knowledge base (KB), but to make information retrieval more efficient, we integrated a state-of-the-art large language model (LLM) with targeted search. This allows users to get precise, context-aware answers without reading through entire articles. The goal is to surface the right information at the right time with minimal effort. Instead of returning dozens of 2,000-word articles to review, users receive a short, bulleted list of text answering their questions. Results are also better as we can use the entire context of a chat history, not a single query. Finally, the whole experience is faster and more intuitive than searching through a knowledge base.

The AI Assistant: How It Works
At a high level, the AI assistant starts with two inputs: the user’s prompt in a chat and the chat’s history. The output is the AI assistant’s response and the sources it used in the answer. Inside, the pipeline consists of three main components:
- A guardrail system that protects the AI assistant against malicious user prompts and prevents the processing of sensitive, personally identifiable information (PII).
- A context search system that retrieves textual context to answer the user’s request from a context database prepared in advance.
- An LLM, the AI assistant’s brain, that processes the user’s prompt, chat history, and provided context.
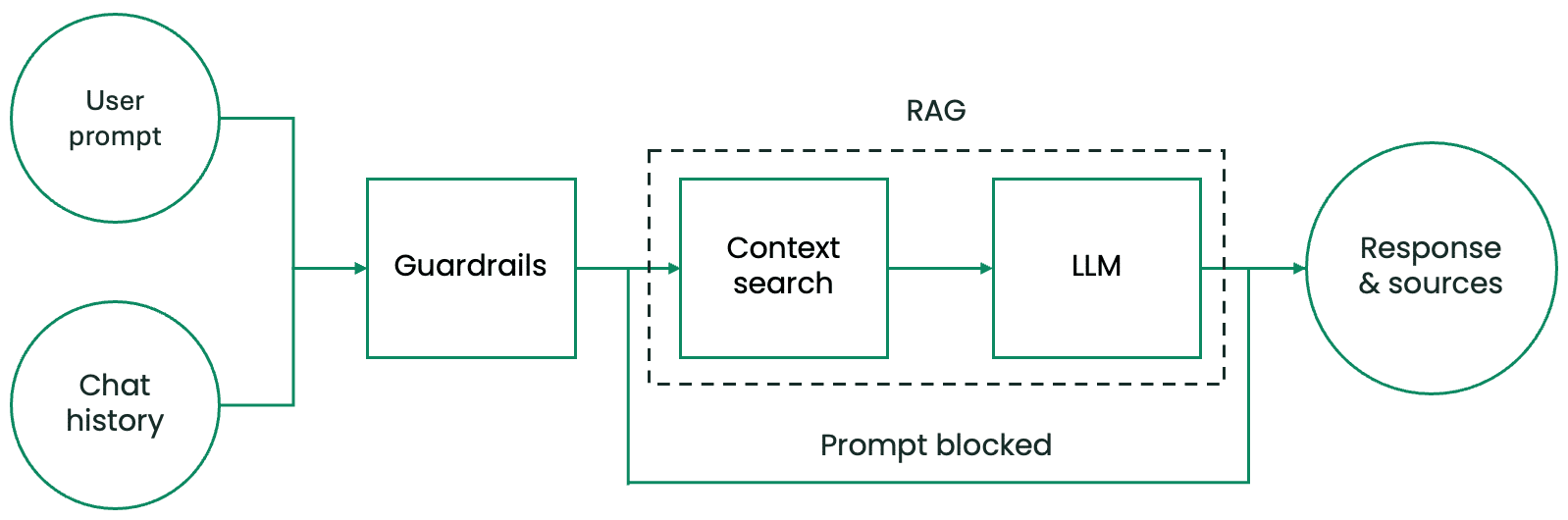
Figure 1. Components of the AI assistant’s pipeline
Part of the power of the AI assistant is its ability to retrieve resources that may relate to a user’s query but do not contain the exact keywords. Instead of a keyword database, our context database contains the semantic meaning of the knowledge base text. Even if words don’t match perfectly, they can still be retrieved as part of the answer to the query. And since, as we’ll see, Cato is not indexing text, the AI assistant is inherently multilingual, allowing any user to pose queries in nearly any language.
Periodically, we scrape our knowledge base, dividing articles into fine-grained chunks and storing the semantic meaning of those text chunks in an Amazon OpenSearch database as numeric vectors called “embeddings.” Representing smaller chunks of text allows us to be more precise in representing them as embeddings and determining their similarity to other concepts. Each embedded chunk is stored with metadata about the original source and its text (see Figure 2). Similar embeddings can then be defined by the distance between them using various metrics, such as the cosine similarity metric (the cosine of the angle between the vectors).
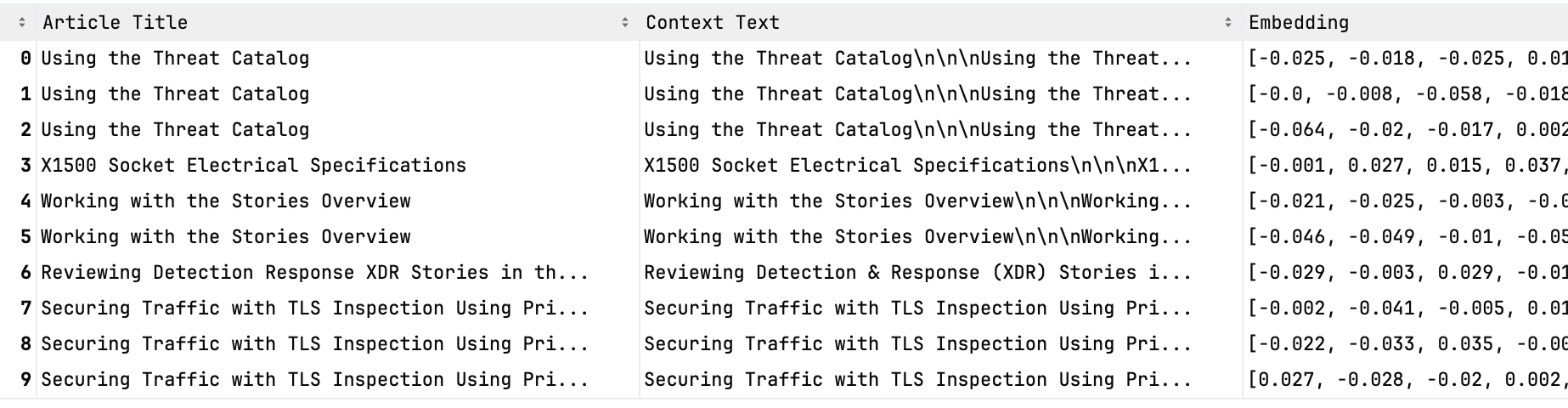
Figure 2. Example of how text is represented in our context database
Retrieval-Augmented Generation (RAG) enhances the AI assistant’s response. Traditional LLMs generate responses based solely on their training data, which remains static after the model is trained. Without external input, they rely on pre-existing knowledge, limiting accuracy and relevance in rapidly changing fields.
RAG enhances this process by incorporating a dynamic information retrieval component. When a user submits a query, we search the context database and retrieve the most semantically similar texts to answer the prompt. We then augment the prompt with relevant text from the knowledge base. Finally, the augmented prompt is sent to a generative model, which now has sources on which to base its response
For example, consider the question, “How do I configure a network rule to block outbound traffic to OpenAI?” A keyword search would return 516 knowledge base articles with the first article being over 2,000 words. Instead, our approach returns a short, bulleted list of step-by-step actions in under 200 words (see demo).
With our approach (see Figure 3), the RAG system returns several embeddings (in blue) whose meaning is closest to the query (in red). Those embeddings correspond to three articles: Configuring Network Rules (upper left), Securing AI App Traffic (bottom), and Internet and WAN Firewall Policies—Best Practices (upper right).

Figure 3. Two-dimensional embeddings of knowledge base article chunks and the user prompt
Conclusion
The AI assistant dramatically saves users time in finding relevant information across Cato’s extensive knowledge base. The pipeline takes a user’s prompt and chat history as input. It produces a response along with relevant sources, relying on a guardrails system for security, a context search system for retrieving relevant knowledge, and an LLM for generating answers. The system uses RAG, where user prompts are embedded into vector representations, searched against a context database of preprocessed knowledge chunks, and combined with retrieved sources to generate informed responses.
Related Articles
Leveraging MAC Address Logic for IoT Classification



