





Cato XDR Storyteller – Wie die Integration generativer KI mit XDR komplexe Sicherheitsvorfälle erklärt



Generative KI (wie OpenAI’s GPT & Co.) hat sich als ein leistungsfähiges Werkzeug bewährt, um Informationen zusammenzufassen oder Text und Code zu transformieren. Zudem besitzt es die hochspezialisierte Fähigkeit, in einer natürlichen menschlichen Sprache zu „sprechen“.
Während unserer Arbeit mit GPT-APIs an mehreren Entwicklungsprojekten kam beim Brainstorming eine interessante Idee auf: Wie gut würde es funktionieren, Informationen, die als raw JSON vorliegen, in natürlicher Sprache zu beschreiben?
Bei den betroffenen Daten handelte es sich um Meldungen aus unserer XDR-Engine, die eine vollständige Zeitleiste von Sicherheitsvorfällen bereitstellt – zusammen mit allen aufgezeichneten Informationen, die mit dem jeweiligen Ereignis zusammenhängen, wie z. B. Traffic-Ströme, Events, Quell-/Zieladressen und mehr.
Bei der Eingabe in den GPT-Mode waren bereits die ersten Ergebnisse (d. h. vor dem Prompt-Engineering) vielversprechend. Und wir sahen großes Potenzial für die Entwicklung einer Methode, mit der ganze Sicherheitsvorfälle in natürlicher Sprache zusammengefasst werden können, um SOC-Teams, die unsere XDR-Plattform nutzen, ein nützliches Tool für die Untersuchung von Vorfällen zur Verfügung zu stellen.

So entstand das Projekt „XDR Story Summary“, auch bekannt als „XDR Storyteller“, das GenAI direkt in die XDR-Erkennungs- und Reaktionsplattform in der Cato Management Application (CMA) integriert.
Die Zusammenfassungen werden damit in natürlicher Sprache präsentiert und bieten eine prägnante Darstellung aller verschiedenen Datenpunkte und der gesamten Zeitachse eines Ereignisses.
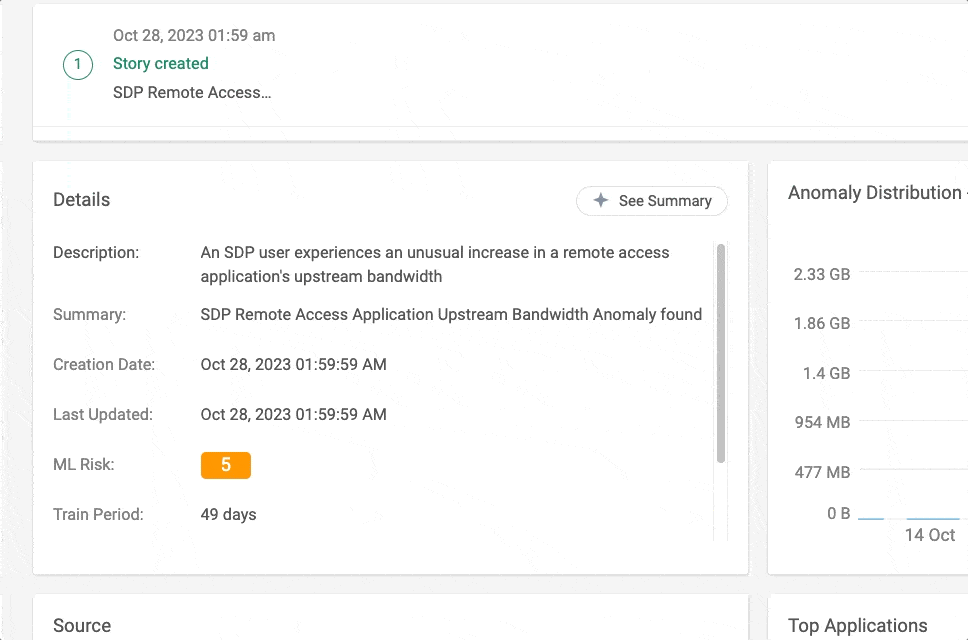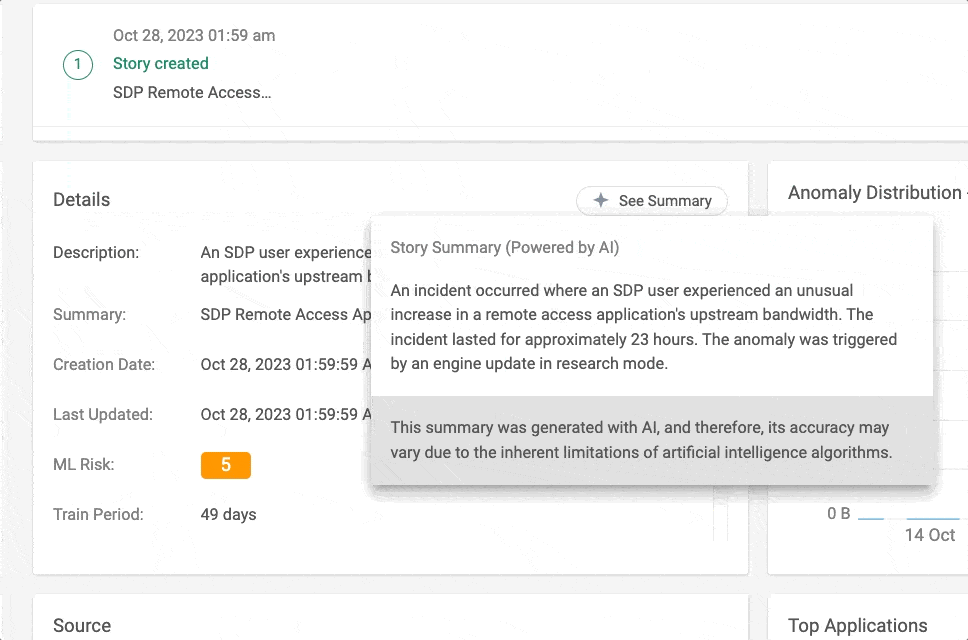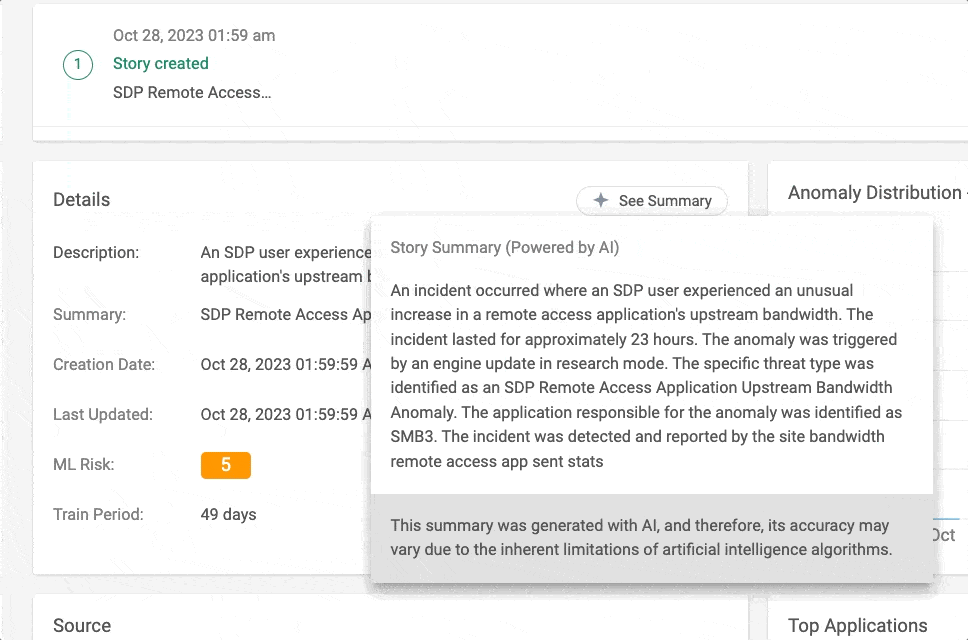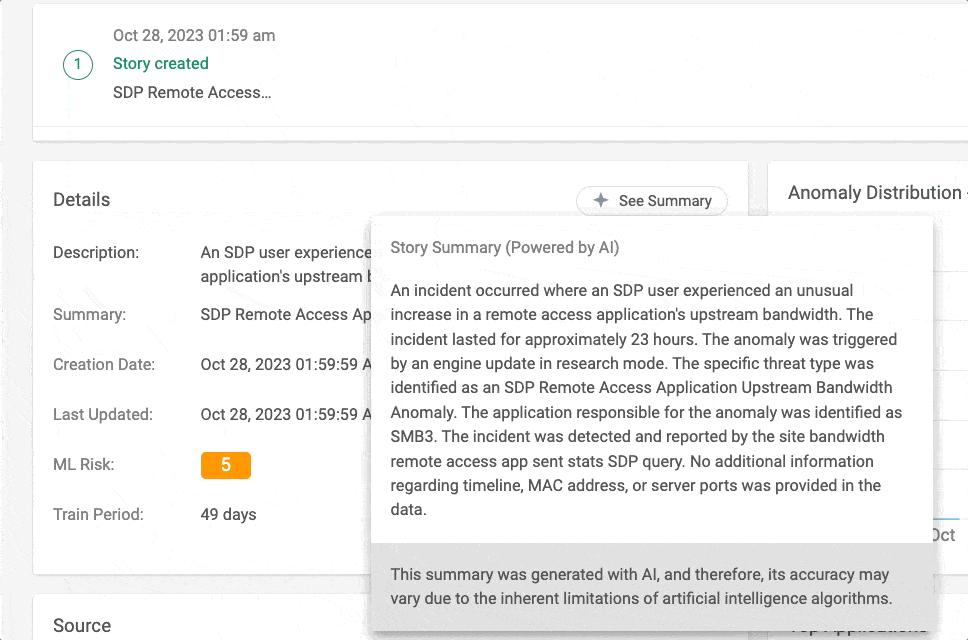
Abbildung 1 – Story Summary in Aktion in der Cato Management Application (CMA)
Das sind nur zwei Beispiele für die vielen verschiedenen Szenarien, die wir vor Beginn der Entwicklung in einem Proof-of-Concept (POC) getestet haben:
Anwendungsfall #1 – tieferer Einblick in die Details eines Vorfalls.
GPT war in der Lage, der KI-Zusammenfassung Details hinzuzufügen, die aus der Benutzeroberfläche der Story nicht leicht zu verstehen waren, da sie aus mehreren Ereignissen besteht.
GPT konnte aus einem SAM-Ereignis (Suspicious Activity Monitoring) ableiten, dass der Benutzer nicht nur versuchte, ein schädliches Skript herunterzuladen, sondern auch die auf dem Endpoint laufenden McAfee- und Defender-Dienste zu deaktivieren.
Die GPT-Darstellung basiert auf dem Lesen von JSON-Rohdaten eines XDR-Events. Sie ist zwar rein textbasiert und steht damit im Gegensatz zur visuellen UI-Darstellung, ist aber dafür in der Lage, Daten aus verschiedenen Kontexten in einer einzigen Zusammenfassung zu vereinen. So gibt sie Einblicke in Aspekte, die durch ihre Komplexität über die UI allein nur schwer zu erfassen sind.
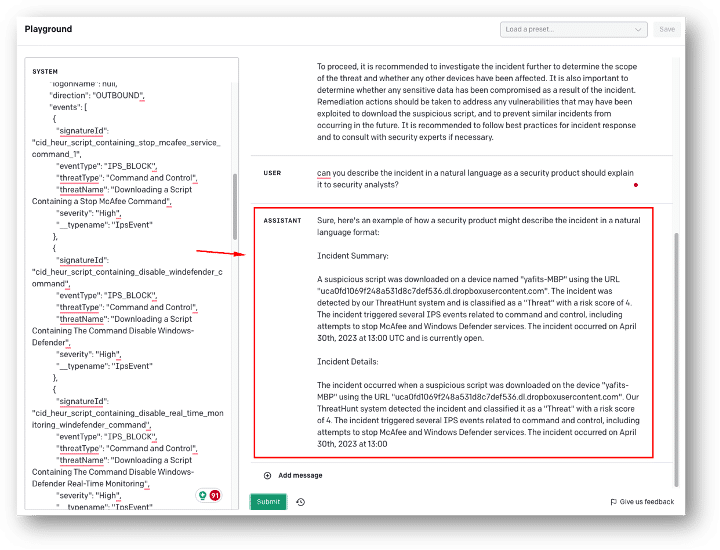
Abbildung 2 – Beispiel für eine Zusammenfassung von JSON-Rohdaten, aus dem OpenAI Playground
Beispiel für Anwendungsfall #2 – Verwendung von unterstützenden Ablaufplänen, um der Zusammenfassung Empfehlungen zur Fehlerbehebung hinzuzufügen.
Dadurch, dass GPT eine zusätzliche Datenquelle zu einem von unseren Support-Teams verwendeten Ablaufplan erhielt, konnte nicht nur ein Netzwerk-Event zusammengefasst, sondern auch eine prägnante Cato-spezifische Handlungsempfehlung zur Behebung oder weiteren Untersuchung des Ereignisses bereitgestellt werden.
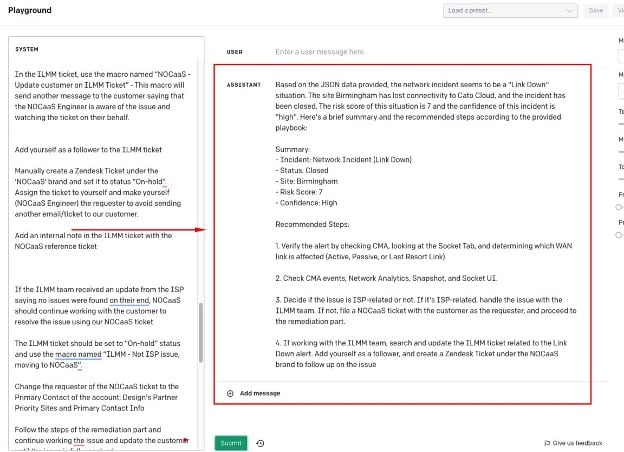
Abbildung 3 – Beispiel für die Bereitstellung von zusätzlichen Datenquellen für GPT, aus dem OpenAI Playground
Auswahl eines GenAI-Models
Bei der Integration eines Drittanbieter-KI-Dienstes (oder jedes anderen Dienstes, der Ihre Daten verarbeitet) sind mehrere Aspekte zu berücksichtigen. Einige sind technischer Natur, wie z. B. die Frage, wie man die besten Ergebnisse aus dem Input erhält; andere sind rechtlicher Natur und betreffen den Umgang mit unseren Daten und denen unserer Kunden.
Bevor Sie die Herausforderungen bei der Arbeit mit einem GenAI-Modell definieren, müssen Sie sich für das Tool entscheiden, das Sie integrieren möchten. Obwohl GPT-4 (OpenAI) aufgrund seiner Popularität und seines beeindruckenden Funktionsumfangs die erste Wahl zu sein scheint, gibt es einige weitere Optionen wie z. B. PaLM (Google), LLaMA (Meta), Claude-2 (Anthropic) und viele andere.
Wir haben uns für einen POC zwischen OpenAIs GPT und Amazons Bedrock entschieden, das eher eine KI-Plattform ist, die es erlaubt, aus einer Liste von mehreren unterstützten FMs (Foundation Models) zu entscheiden, welches Model verwendet werden soll.
The Industry’s First SASE-based XDR Has Arrived | Download the eBookWir wollen in diesem Beitrag nicht zu sehr auf die Details des POC eingehen und kommen gleich zum Ergebnis, nämlich, dass wir unsere Lösung mit GPT integriert haben. Beide Lösungen zeigten gute Ergebnisse. Der Weg über Amazon Bedrock hätte inhärente Vorteile in Bezug auf die rechtlichen und datenschutzrechtlichen Aspekte der Verlagerung von Kundendaten nach außen gehabt, und zwar:
- Amazon ist ein bestehender Sub-Prozessor, da wir AWS auf unserer Plattform weithin nutzen.
- Es ist möglich, Ihre eigene Virtual Private Cloud (VPC) mit Bedrock zu verbinden und so die Verlagerung von Datenverkehr über das Internet zu vermeiden.
Dennoch haben wir uns aufgrund anderer technischer Überlegungen für GPT entschieden und die Datenschutzfrage auf andere Weise gelöst, auf die wir weiter unten eingehen werden.
Ein weiterer erwähnenswerter positiver Effekt des POC war, dass wir ein Model-unabhängiges Design entwickeln konnten, das die Option offen lässt, in Zukunft weitere KI-Quellen hinzuzufügen und so die Zuverlässigkeit und Redundanz zu verbessern.
Herausforderungen und Lösungen
Schauen wir uns die Herausforderungen und Lösungen bei der Entwicklung der „Storyteller“-Funktion an:
Prompt Engineering & Kontext – Für jede Aufgabe, die einer KI gestellt wird, ist es wichtig, sie richtig abzugrenzen und der KI genug Kontext zu geben, um ein optimales Ergebnis zu erzielen.
Wenn Sie ChatGPT zum Beispiel fragen: „Erkläre die thermonukleare Energie“ und „Erkläre die thermonukleare Energie für einen Physik-Doktoranden“, werden Sie sehr unterschiedliche Ergebnisse erhalten. Dasselbe gilt für die Cybersicherheit. Da sich die gewünschte Ausgabe an Sicherheits- und Betriebspersonal richtet, sollten wir der KI daher den richtigen Kontext geben, z. B. „Sie sind ein MDR-Analyst, erstellen Sie eine umfassende Zusammenfassung, deren Empfänger der Kunde ist.“
Um den Kontext zu verbessern, fügen wir neben dem zu analysierenden Quell-JSON auch Quellmaterial hinzu, das GPT für die Antwort verwenden soll.
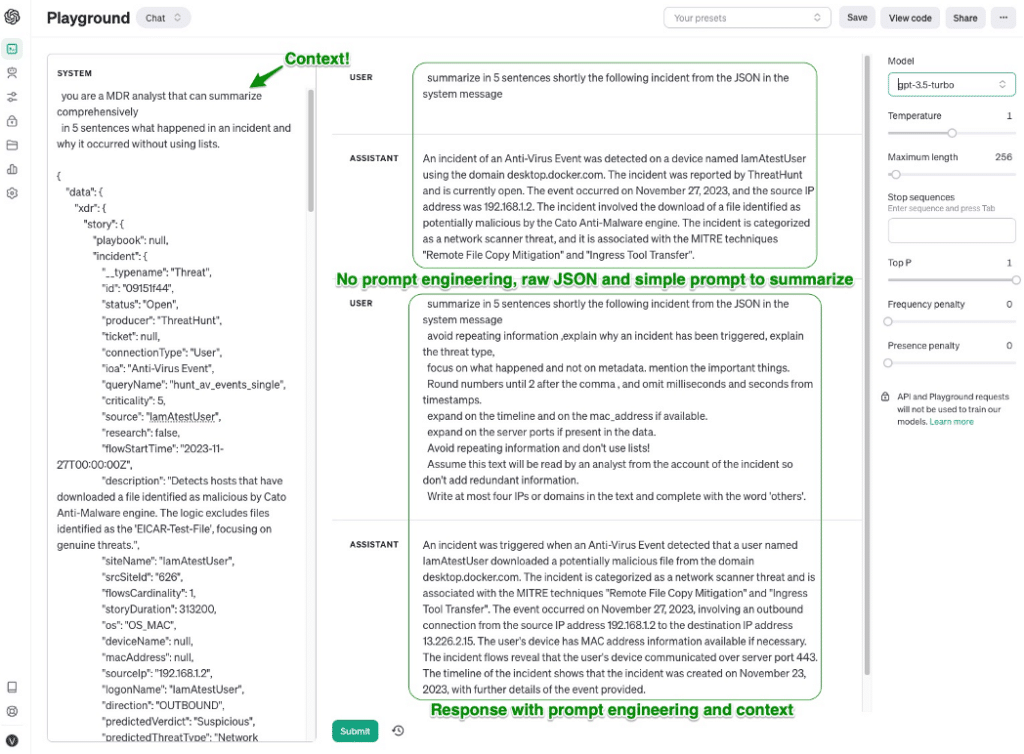
Abbildung 4 – Beispiel für Prompt-Engineering-Forschung aus dem OpenAI Playground
Zusätzliche Prompt-Anweisungen können helfen, die Formatierung und Ausführlichkeit der Ausgabe zu kontrollieren. Eine bekannte Eigenschaft von GenAIs ist, dass sie gerne plappern und übermäßig lange Antworten geben können, oft mit sich wiederholenden Informationen. Da sie aber (vorerst…) folgsam sind, können wir die Antworten gestalten, indem wir Anweisungen wie „Vermeide die Wiederholung von Informationen“ oder „Interpretiere die Informationen, beschreibe sie nicht einfach“ zu den Prompts hinzufügen.
So können selbsterklärende Anweisungen wie „Verwende keine Listen„, „Runde Zahlen, wenn sie zu lang sind“ oder „Verwende das ISO-8601 Datumsformat“ das Endergebnis beeinflussen.
Datenschutz – ein kritischer Aspekt bei der Zusammenarbeit mit einer Drittanbieter-Lösung, an die Kundendaten übermittelt werden, die auch personenbezogene Daten enthalten. Diese Daten unterliegen natürlich auch den strengen Compliance-Zertifizierungen, die Cato einhält, wie SOC2, DSGVO usw.
Wie bereits erwähnt, kann dies unter bestimmten Umständen, z. B. bei der Nutzung von AWS, dadurch gelöst werden, dass man alles in der eigenen VPC hält. Bei der Verwendung der API von OpenAI war aber ein anderer Ansatz erforderlich.
Erwähnenswert ist, dass OpenAI im Enterprise-Tarif garantiert, dass Ihre Prompts und Daten NICHT für das Training ihres Models verwendet werden. Auch andere datenschutzrelevante Aspekte wie die Kontrolle der Datenaufbewahrung sind hier verfügbar, aber dennoch wollten wir dieses Problem auf unserer Seite angehen und keine personenbezogenen Daten (Personal Identifiable Information, PII) senden.
Die Lösung bestand darin, alle Felder, die PII-Informationen enthalten, vor dem Senden durch Tokenisierung zu verschlüsseln. PII-Informationen sind in diesem Zusammenhang definiert als alles, was Aufschluss über den Nutzer oder seine spezifischen Aktivitäten gibt, z. B. Quell-IP, Domänen, URLs, Geolocation usw.
In Tests haben wir festgestellt, dass das Nichtversenden dieser Daten keine negativen Auswirkungen auf die Qualität der Zusammenfassung hat, so dass wir vor dem Kompilieren der Rohdaten, die zur Zusammenfassung gesendet werden sollen, eine Vorverarbeitung der Daten vornehmen. Auf der Grundlage einer vorgegebenen Liste von Feldern, die unverändert gesendet werden können (oder nicht), bereinigen wir die Rohdaten. Wir behalten eine Zuordnung aller verschlüsselten Werte bei und ersetzen nach Erhalt der Antwort die verschlüsselten Werte durch die vertraulichen Felder, um eine vollständige und lesbare Zusammenfassung zu erhalten, ohne dass sensible Kundendaten jemals unsere eigene Cloud verlassen.
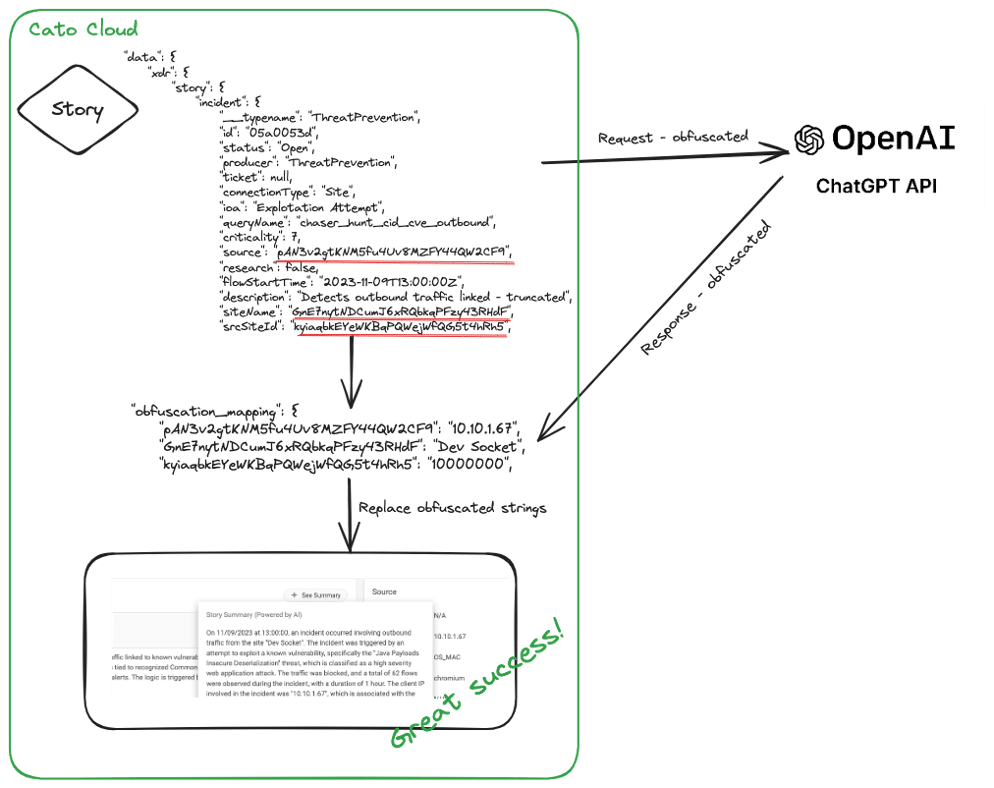
Abbildung 5 – High-Level-Flow der PII-Verschleierung
Ratenbegrenzung – Wie die meisten Cloud-APIs wendet auch OpenAI verschiedene Ratenlimits für Anfragen an, um die eigene Infrastruktur vor Überlastung zu schützen. OpenAI tut dies, indem es den Nutzern eine Tarif-basierte Limit-Berechnung auf der Grundlage ihrer Gesamtnutzung zuweist. Dies ist insgesamt eine ausgezeichnete Praxis, doch beim Entwurf eines Systems, das eine solche API nutzt, müssen bestimmte Aspekte berücksichtigt werden:
- Der Code sollte optimiert werden (sollte er das nicht immer? 😉 ), um die begrenzten Ressourcen – Anzahl der Anfragen pro Minute/Tag oder Anfrage-Token – nicht zu „verbrauchen“.
- Die Messung der Rate und der verbleibenden Token kann mit OpenAI durch Hinzufügen spezifischer HTTP-Anfrage-Header (z.B. „x-ratelimit-remaining-tokens“) und die Betrachtung der verbleibenden Limits in der Antwort erfolgen.
- Error Handling im Falle des Erreichens eines Limits unter Verwendung von Backoff-Algorithmen oder einfaches Wiederholen der Anfrage nach einer kurzen Zeitspanne.
Teil von etwas Größerem
Ähnlich wie der gesamte Bereich der KI selbst, dessen Entwicklung und Anwendung wir gerade erleben, werden auch die verschiedenen Anwendungen im Bereich der Cybersicherheit noch erforscht und erweitert. Bei Cato Networks investieren wir weiterhin stark in KI- und ML-basierte Technologien auf unserer gesamten SASE-Plattform.
Dazu gehört unter anderem die Integration zahlreicher Machine-Learning-Modelle in unsere Cloud für Inline- und Out-of-Band-Schutz und -Erkennung (wir werden in kommenden Blogbeiträgen darauf eingehen) und natürlich Funktionen wie der in diesem Beitrag beschriebene XDR Storyteller, der GenAI für eine vereinfachte und gründlichere Analyse von Sicherheitsvorfällen nutzt.
Weitere Artikel


Cato Networks erweitert Plattform zur Bereitstellung der ersten SASE-nativen IoT/OT-Sicherheitslösung der Branche


Wenn SASE auf DEM trifft: Die Revolution der User Experience

