






Cato 新AIアシスタントの全貌に迫る


卓越したカスタマーエクスペリエンスを提供するという理念に基づき、Cato NetworksはCato SASE Cloud Platformの一部としてナレッジベースのAIアシスタントを追加しました。このAIアシスタントは、Catoの多彩な機能の使い方に関する質問に対し、ユーザーの状況や環境に合わせた詳細な段階的手順を含む、正確かつ適切な回答を提供します。
これは、CatoのAIへの取り組みの最新事例にすぎません。当社は、生成AI(GenAI)機能の基盤としてAmazon Bedrockを採用したことを最近発表しました。Amazon Bedrockは、当社のAIアシスタントだけでなく、自然言語検索(NLS)にも活用されており、自由形式のテキスト入力をSASEプラットフォーム上の技術的な検索フィルターへと変換することを可能にします。CatoのAIおよびMLページでは、脅威インテリジェンス、脅威の防止、クライアント・デバイス・アプリケーションの分類など、AI/ML技術を活用したさまざまな事例をさらに紹介しています。
なぜ情報検索機能付きAIアシスタントなのか?
Catoはこれまでもナレッジベース(KB)内で強力な検索機能を提供してきましたが、情報検索をさらに効率化するために、最先端の大規模言語モデル(LLM)とターゲット検索を統合しました。これによりユーザーは、記事全体を読むことなく、文脈を踏まえた正確な回答を得ることができます。目指しているのは、労力を最小限とし、必要な情報を必要なタイミングで提示することです。ユーザーには2,000語におよぶ記事を何十本も提示する代わりに、質問への回答を簡潔にまとめた箇条書きのリストが提供されます。単一のクエリではなく、チャット履歴全体の文脈を活用できるため、より的確な回答が得られます。さらに、ナレッジベース内を検索するよりも、全体的に迅速かつ直感的です。

AIアシスタントの仕組みとは
概要として、まずAIアシスタントは、ユーザーのチャットでの入力とチャット履歴という2つの情報をもとに処理を開始します。出力されるのは、AIアシスタントの回答と、その回答に使用された情報源です。内部の処理は、主に次の3つのコンポーネントで構成されています。
- 悪意のあるユーザー入力からAIアシスタントを保護し、機密情報や個人を特定できる情報(PII)の処理を防ぐガードレールシステム。
- 事前に用意されたコンテキストデータベースから、ユーザーのリクエストに応じたテキスト情報を検索・取得するコンテキスト検索システム。
- ユーザーの入力、チャット履歴、提供されたコンテキストを処理する、AIアシスタントの頭脳にあたる大規模言語モデル(LLM)。
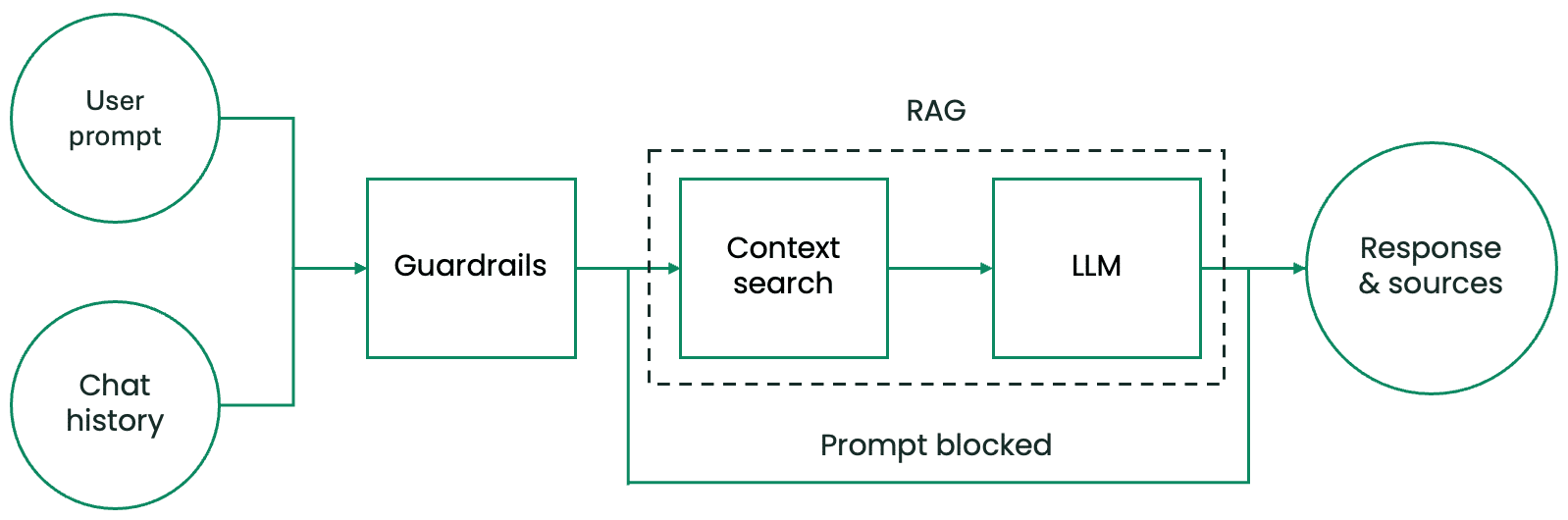
図1.AIアシスタント処理パイプラインの構成要素
AIアシスタントの強みのひとつは、ユーザーのクエリに関連する可能性があるものの、完全に一致するキーワードを含まないリソースを検索・取得できる点です。キーワードベースのデータベースではなく、当社のコンテキストデータベースにはナレッジベースのテキストの意味的な情報が格納されています。 たとえ単語が完全に一致しなくても、クエリの回答の一部として取得される可能性があります。後述しますが、Catoはテキストのインデックス化を行っていないため、AIアシスタントは本質的に多言語対応となっており、ほぼすべての言語でクエリを入力することが可能です。
定期的にナレッジベースをスクレイピングし、記事を細かい単位に分割したうえで、それらのテキスト片の意味情報を「埋め込み(embedding)」と呼ばれる数値ベクトルとしてAmazon OpenSearchデータベースに保存しています。より小さなテキスト単位に分割することで、それぞれを埋め込み(embedding)としてより正確に表現でき、他の概念との類似性をより的確に判定することが可能になります。各埋め込みデータには、元となる情報源やそのテキストに関するメタデータが付与されて保存されます(図2参照)。類似した埋め込みデータは、ベクトル間の距離によって定義され、たとえばコサイン類似度(ベクトル間の角度のコサイン値)などのさまざまな指標を用いて測定されます。
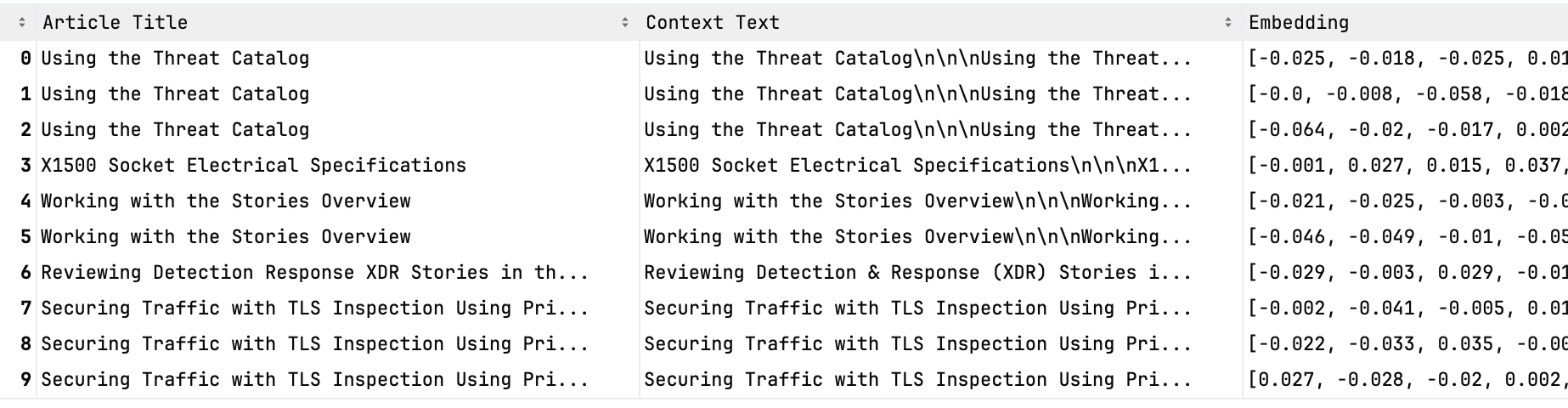
図2.当社のコンテキストデータベースにおけるテキストの表現例
Retrieval-Augmented Generation(RAG)は、AIアシスタントの回答精度を高める手法です。従来の大規模言語モデル(LLM)は、学習後に固定されたトレーニングデータのみに基づいて応答を生成します。外部からの情報入力がない場合、事前に学習された知識のみに依存するため、変化の激しい分野においては正確性や関連性が制限されます。
RAGは、このプロセスに動的な情報検索コンポーネントを組み込むことで強化を図ります。ユーザーがクエリを送信すると、コンテキストデータベースを検索し、意味的に最も近いテキストを取得してその問いに対する回答を導き出します。その後、ナレッジベースから取得した関連テキストをプロンプトに追加します。最後に、拡張されたプロンプトが生成モデルに送られ、モデルはその情報源に基づいて回答を生成します。
たとえば、「OpenAIへの送信トラフィックをブロックするネットワークルールをどのように設定すればよいですか?」という質問をするとしましょう。キーワード検索では、516件のナレッジベース記事が表示され、最初の記事は2,000語を超える長文になります。一方、当社のアプローチでは、200語未満の簡潔な箇条書き形式で、段階的手順が提示されます(デモ参照)。
当社のアプローチでは(図3参照)、RAGシステムがクエリ(赤)に最も意味的に近い複数の埋め込みデータ(青)を返します。これらの埋め込みデータは、次の3つの記事に対応しています。「ネットワークルールの設定」(左上)、 「AIアプリのトラフィック保護」(下)、「インターネットおよびWANファイアウォールポリシーのベストプラクティス」(右上)に対応しています。

図3.ナレッジベース記事のチャンクおよびユーザープロンプトの2次元埋め込み表現
結論
AIアシスタントは、Catoの膨大なナレッジベースの中から関連情報を探す時間を大幅に短縮します。このパイプラインは、ユーザーのプロンプトとチャット履歴を入力として受け取り、関連する情報源とともに回答を生成します。セキュリティのためのガードレールシステム、関連知識を取得するためのコンテキスト検索システム、そして回答を生成する大規模言語モデル(LLM)に基づいて動作します。またこのシステムはRAG(Retrieval-Augmented Generation)を採用しており、ユーザープロンプトをベクトル表現に変換し、事前処理されたナレッジチャンクのコンテキストデータベースと照合します。その後、取得された情報源と組み合わせて、根拠のある回答を生成します。
Catoの革新的なMSASEパートナープラットフォーム:サービスプロバイダーに休まるの時間を


Cato Networks、2024年 Gartner Magic Quadrantのシングルベンダー SASE 部門においてリーダーに認定


Cato CTRLが新たなSASE脅威レポートを発行


